论文:Scaling Atomistic Protein Binder Design with Generative Pretraining and Test-Time Compute
来源:ICLR 2026
机构:NVIDIA
官网:https://research.nvidia.com/labs/genair/proteina-complexa
代码:https://github.com/NVIDIA-Digital-Bio/proteina-complexa
论文评审:https://openreview.net/forum?id=qmCpJtFZra
Proteina-Complexa:统一生成式预训练与推理时间优化的蛋白质结合剂设计阅读全文
mBER: 一种colabdesign范式的抗体设计方案阅读全文
2025年9月28日, George Church(哈佛教授,基因组学大佬,搞出蛋白条形码的那个)创业的Manifold Bio公司
发表了一篇《mBER: Controllable de novo antibody design with million-scale experimental screening》.这篇文章总体思路是很典型的后BinderCraft作品,最大的一个亮点是同当初的Chai Discovery那样, 在大量的靶点上拿到了Hit.那么究竟如何,让我们细细阅读分析.
代码仓库: GitHub - manifoldbio/mber-open
开源许可: MIT
自定义windows 右键菜单
阅读全文
右键菜单的配置可以通过修改注册表实现。其基本项架构是如下配置,其中 command 参数可以是 %1 或 %V 或 %V %1 或 %V %1 %2 等。不同位置右键的配置位置不同,可以分为三类。1
2
3
4
5XXX/
(Default)='通过 XXX打开'
Icon='C:\Users\Administrator\Desktop\XXX.exe'
command/
(Default)="`"$exe_path`" `"%1`""
选中文件时的右键菜单:
相关内容在 Registry::HKEY_CLASSES_ROOT\*\shell 下。
1 | $exe_path='C:\Users\Administrator\Desktop\Cursor.exe' |
选中文件夹时的右键菜单:
相关内容在 Registry::HKEY_CLASSES_ROOT\Directory\shell 下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$reg_base_path='Registry::HKEY_CLASSES_ROOT\Directory\shell'
$program_name='Cursor'
$message='通过Cursor打开'
$reg_path="$reg_base_path\$program_name"
$reg_command_path="$reg_path\command"
if (-not (Test-Path $reg_path)) {
New-Item $reg_path -Force
}
Set-ItemProperty -Path $reg_path -Name '(Default)' -Value $message
New-ItemProperty -Path $reg_path -Name 'Icon' -Value $exe_path
New-Item -Path $reg_command_path -Force
Set-ItemProperty -Path $reg_command_path -Name '(Default)' -Value "`"$exe_path`" `"%1`""
选中文件夹背景时的右键菜单:
相关内容在 Registry::HKEY_CLASSES_ROOT\Directory\Background\shell 下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$reg_base_path='Registry::HKEY_CLASSES_ROOT\Directory\Background\shell'
$program_name='Cursor'
$message='通过Cursor打开'
$reg_path="$reg_base_path\$program_name"
$reg_command_path="$reg_path\command"
if (-not (Test-Path $reg_path)) {
New-Item $reg_path -Force
}
Set-ItemProperty -Path $reg_path -Name '(Default)' -Value $message
New-ItemProperty -Path $reg_path -Name 'Icon' -Value $exe_path
New-Item -Path $reg_command_path -Force
Set-ItemProperty -Path $reg_command_path -Name '(Default)' -Value "`"$exe_path`" `"%V`""
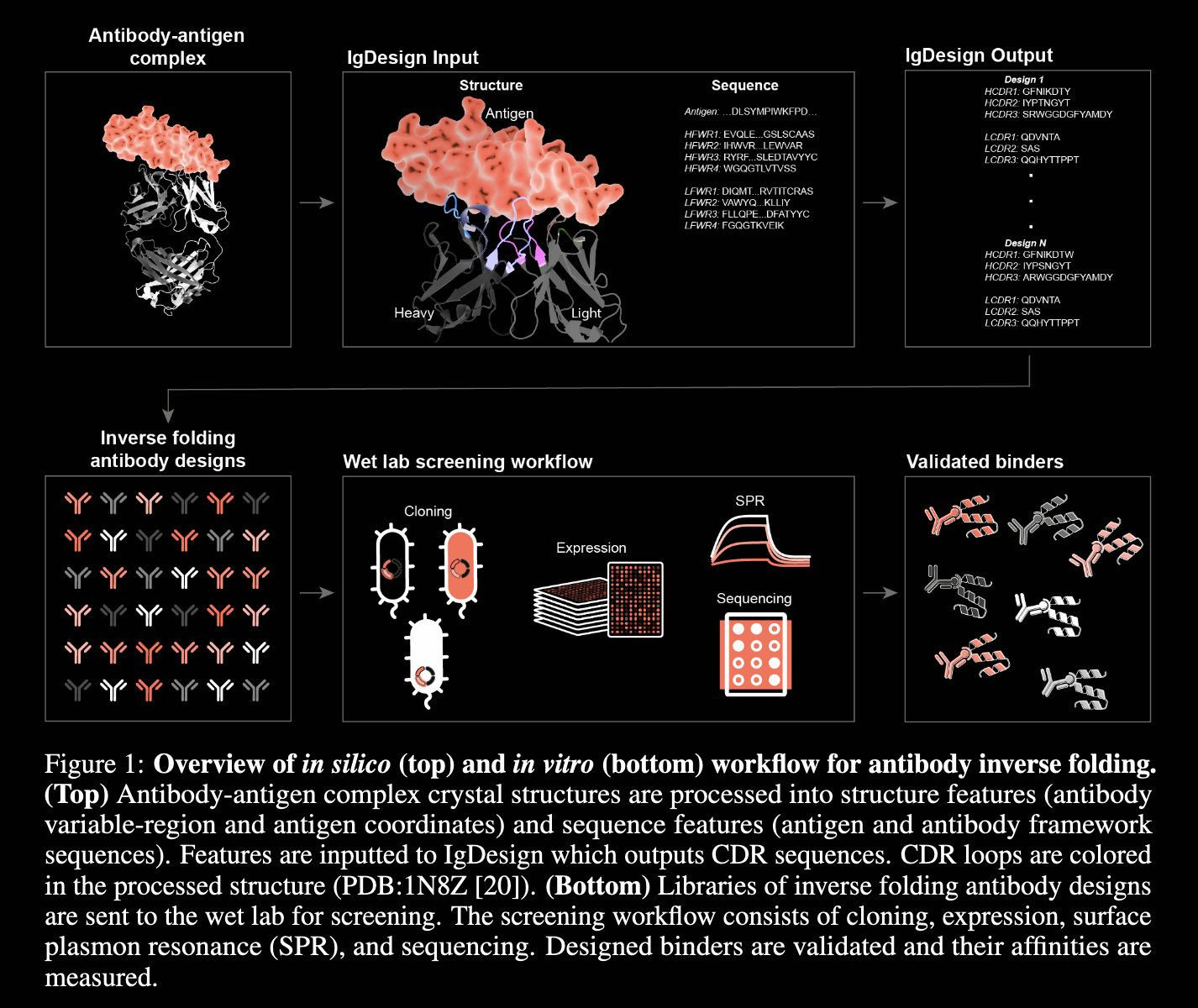
AIDA:基于抗原结构与抗体序列的抗体设计方法-滑铁卢大学阅读全文
2024年12月7日,滑铁卢大学的Ghodsi团队发表题为“Conditional Sequence-Structure Integration: A Novel Approach for Precision Antibody Engineering and Affinity Optimization”的抗体从头设计算法AIDA。
PPB-Affinity:整合多个数据源的PPI亲和力数据集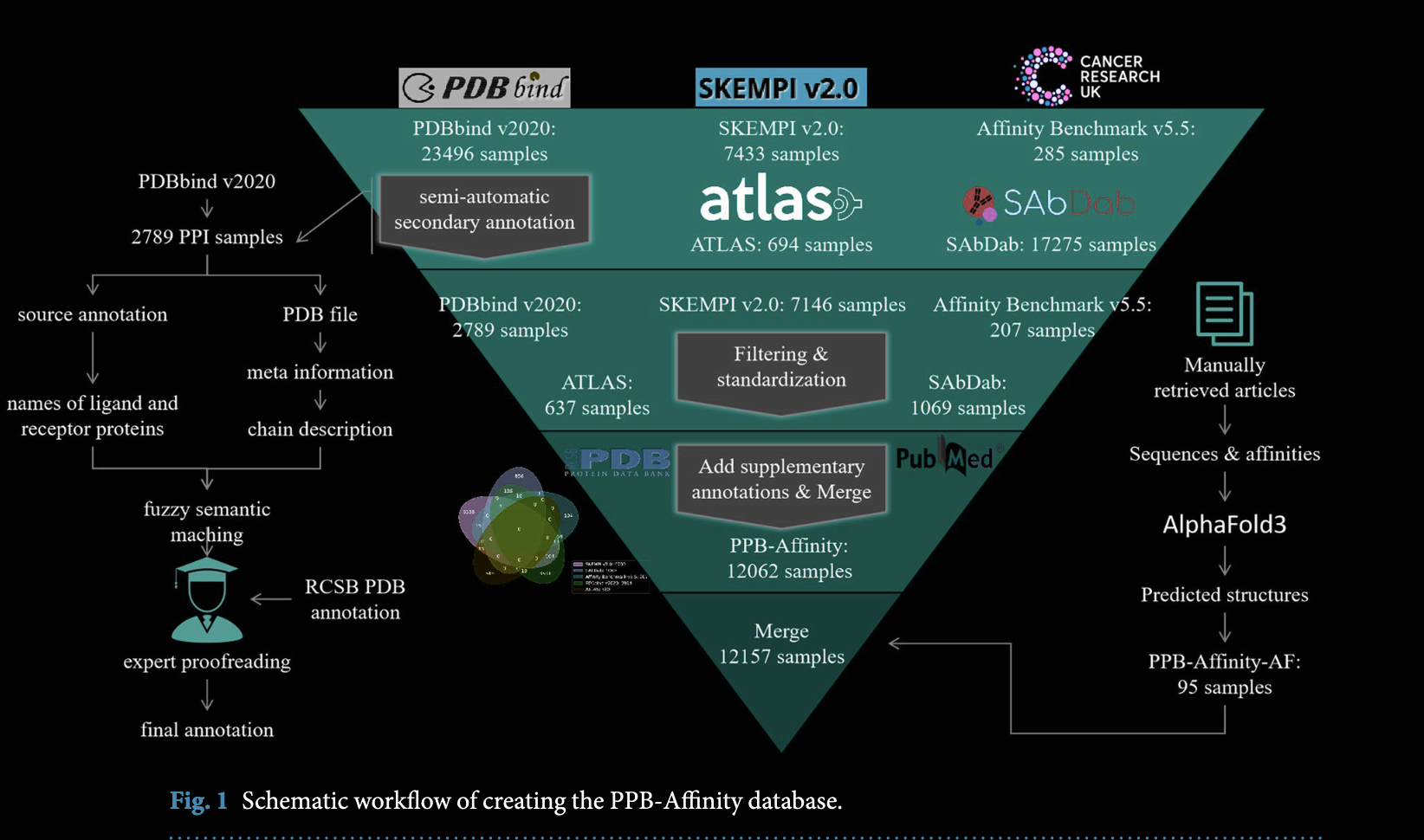 阅读全文
阅读全文
2024年12月3日,清华大学珠三角研究院人工智能创新中心的韩蓝青研究团队在Nature Scientific Data上在线发表了PPB-Affinity: Protein-Protein Binding Affinity dataset for AI-based protein drug discovery,整合了SKEMPI v2.0、PDBbind 2020和SabDab等数据源,整理构建一个PPI亲和力数据集,并基于IPA构建一套benchmark算法验证了数据集的价值。
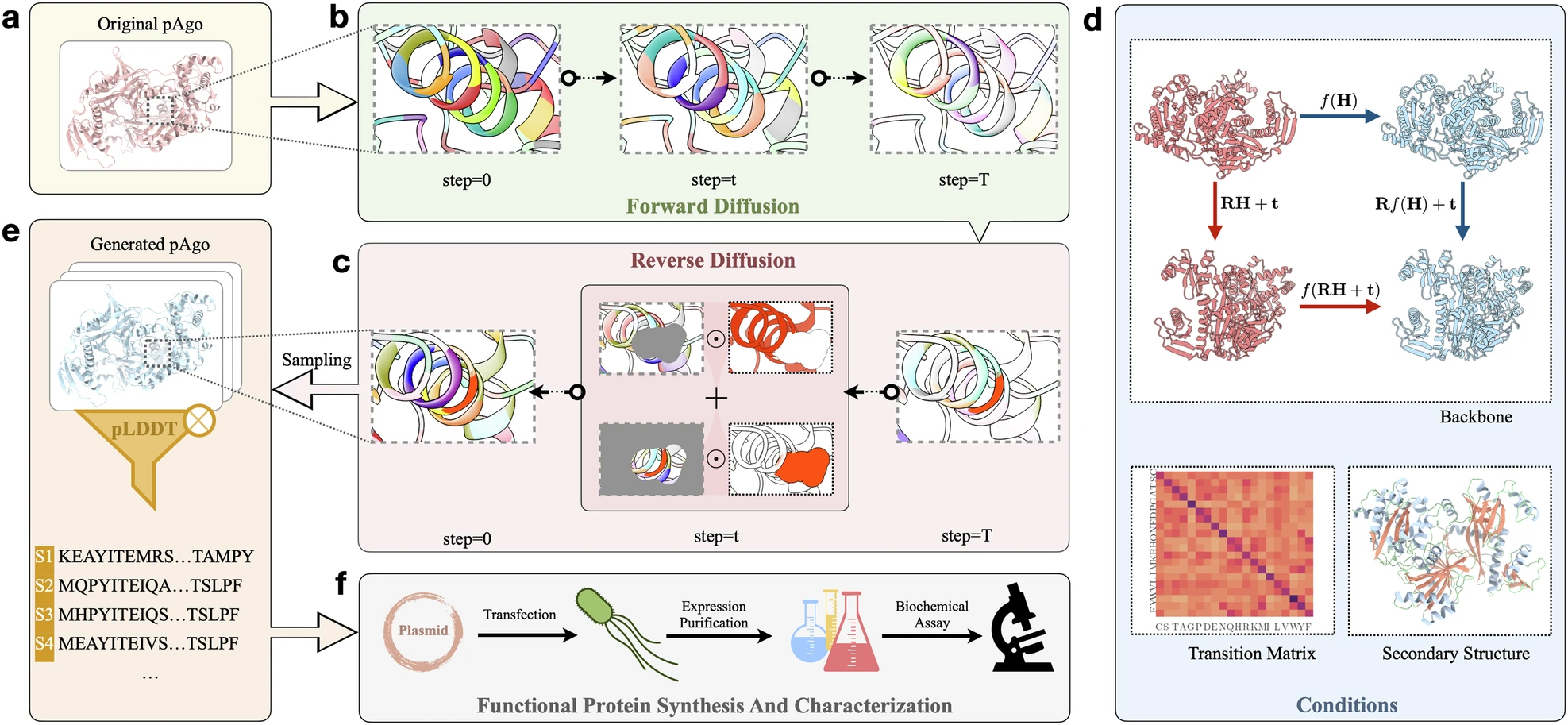
CPDiffusion蛋白序列扩散算法-洪亮阅读全文
本文是上交大洪亮团队发表在Nature Cell Discovery上的工作,提出了一种基于扩散的蛋白序列生成算法CPDiffusion。算法CATH 4.2和pAgo蛋白上训练,验证了其denovo生成的pAgo和KmAgo蛋白的生物活性。
- 论文地址:A conditional protein diffusion model generates artificial programmable endonuclease sequences with enhanced activity
- 开源信息:
- 代码仓库:GitHub - bzho3923/CPDiffusion
- 模型仓库:HuggingFace - tyang816/CPDiffusion
- 模型许可:Apache 2.0
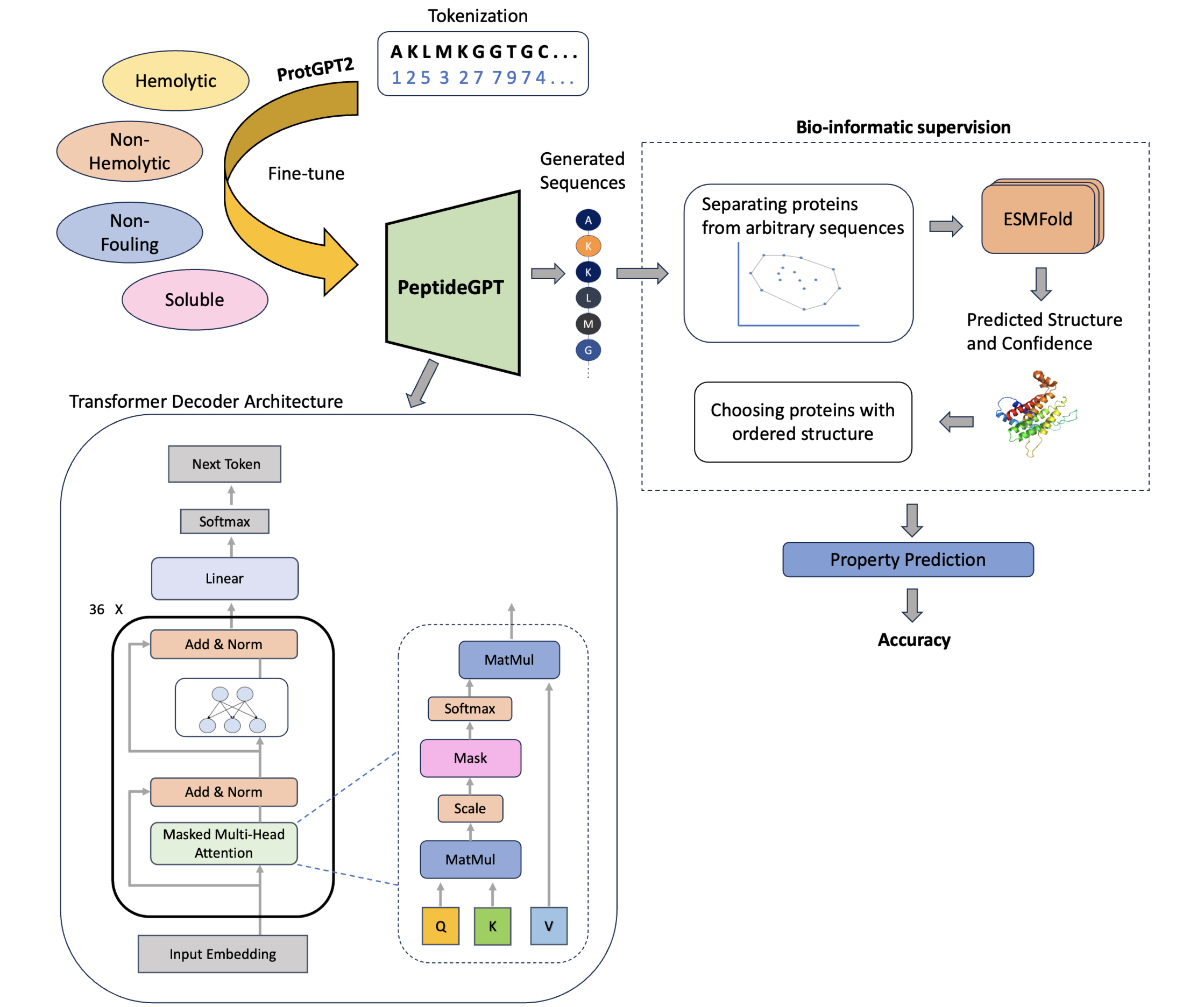
PeptideGPT多功能多肽生成模型-卡内基梅隆大学
阅读全文
DPLM扩散蛋白语言模型-字节跳动ICML2024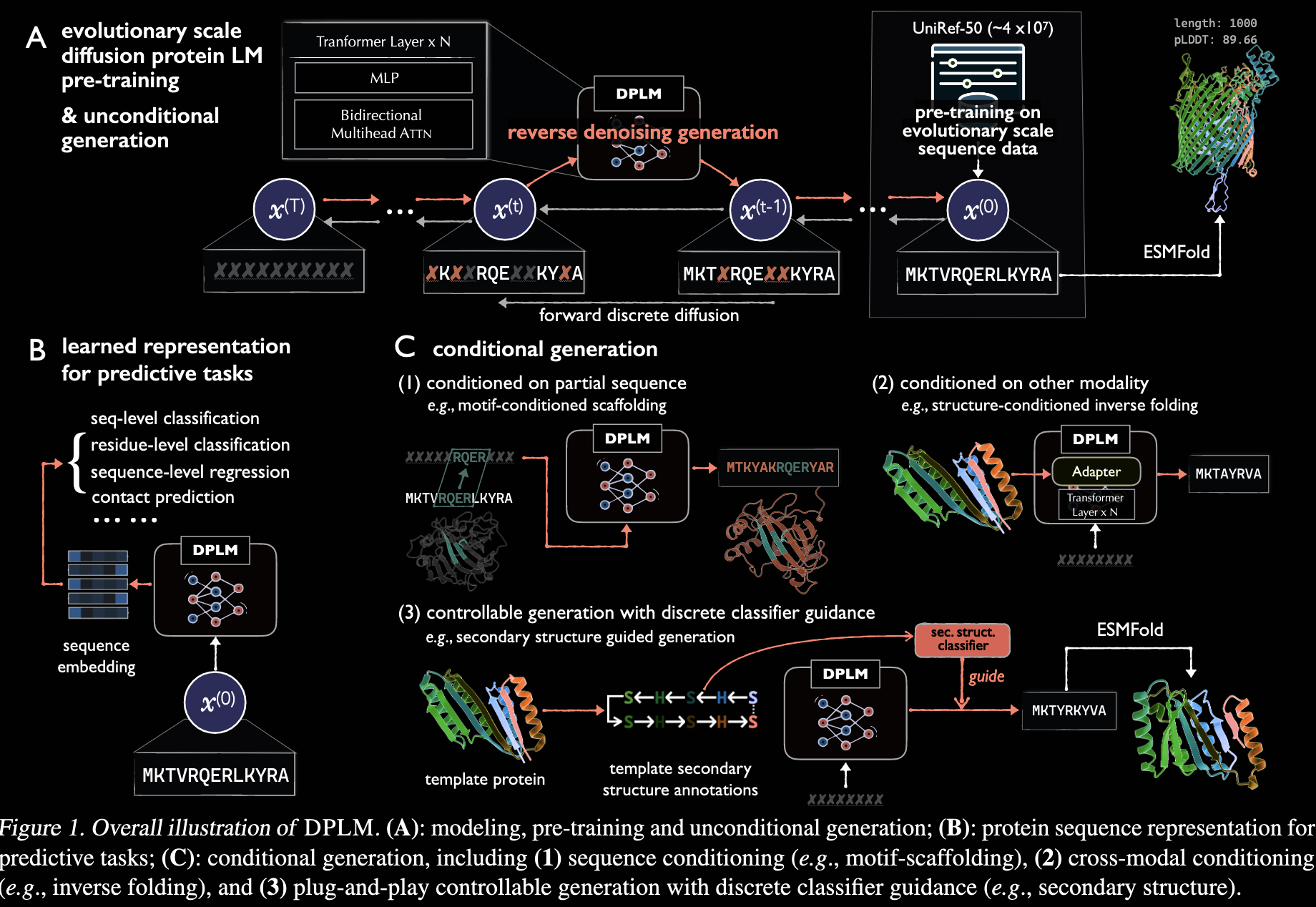 阅读全文
阅读全文
原文链接:Diffusion Language Models Are Versatile Protein Learners
开源信息:GitHub - bytedance/dplm,Apache 2.0 License。
DPLM是字节跳动在ICML2024上提出的一种基于扩散的语言模型,用于蛋白质序列的生成。